Introducing Supervisely Synthetic Crack Segmentation Dataset

We present our synthetic dataset for road surface crack segmentation that was generated automatically, available for research purposes.

Table of Contents
This tutorial is for those who want to create their own synthetic training dataset. We also provide ready-to-use Supervisely Apps in Ecosystem that will perform many routine tasks for you.
This blog post is the Part 2 in the series of posts where we share results of our experiments on leveraging synthetic training data to get the accurate and robust semantic segmentation model on very challenging tasks - cracks segmentation:
- Part 1. How to Train Interactive Smart Tool for Precise Cracks Segmentation in Industrial Inspection
- Part 2. 👉 Introducing Supervisely Synthetic Crack Segmentation Dataset
- Part 3. Lessons Learned From Training a Segmentation Model On Synthetic Data
- Part 4. Unleash The Power of Domain Adaptation - How to Train Perfect Segmentation Model on Synthetic Data with HRDA
Download Dataset
Before we started, you can check the dataset itself in 🥷 Dataset Ninja — a new dataset catalog focused on quality and convenient tools for data scientists. View images along with annotations, explore various statistics, download data in Supervisely format and much more!










Supervisely Synthetic Crack Segmentation
Supervisely Synthetic Crack Segmentation is a dataset for a semantic segmentation of cracks in industrial inspection. Obtaining real-world annotated data for crack segmentation can be challenging. The detailed, pixel-perfect nature of segmentation requires extensive labor and often expert knowledge, making the process time-consuming and costly. Synthetic data offers a promising solution to these challenges. It provides a controlled, cost-effective, and automated alternative to real-world data collection and manual annotation..
Get in Dataset Ninja
Motivation
Obtaining real-world annotated data for crack segmentation can be challenging. The detailed, pixel-perfect nature of segmentation requires extensive labor and often expert knowledge, making the process time-consuming and costly.
Synthetic data offers a promising solution to these challenges. It provides a controlled, cost-effective, and automated alternative to real-world data collection and manual annotation.
Benefits of using synthetic data
Using synthetic data offers several benefits:
-
Cost-Effective: Eliminates the extensive costs associated with real-world data collection and annotation.
-
Controlled Environments: Provides the flexibility to create specific scenarios, control external factors, and adjust variables, ensuring a diverse and comprehensive dataset.
-
Scalability: Allows for the rapid generation of large datasets, aiding in training more robust models.
-
Consistency & Quality: Ensures consistent annotations and can generate high-quality data without the noise or variations commonly found in real-world datasets.
-
Privacy & Security: Bypasses potential privacy concerns or security issues associated with real-world data, as synthetic data doesn't contain sensitive or personal information.
Dataset Creation Process
The overall idea of creating this dataset is simple: we will collect textures of real materials, such as asphalt, wall, concrete, etc, and then draw cracks on them. Of course, naively drawing generated lines of cracks to a texture will look unrealistic, so we also need to work on composition & post-processing.
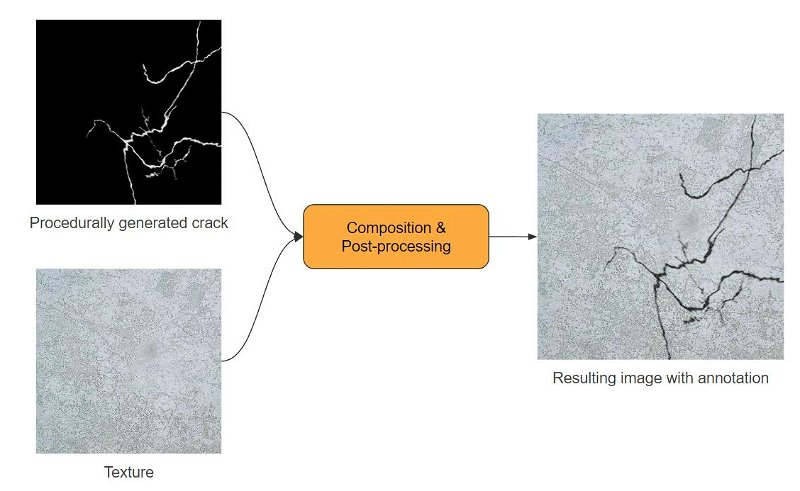 The main concept of generating images
The main concept of generating images
Thus, the entire creation process can be divided into three stages:
-
Collect textures of real materials
-
Implement procedural crack generation
-
Composition & Post-processing
After these steps, we can just run the generation script and create as much data as we need. Let's take a detailed look at each stage!
Step 1. Collect textures of real materials

Flickr downloader
Downloads images from the Flickr to the dataset.

Pexels downloader
Downloads images and videos from Pexels.

Prompt-based Image Filtering with CLIP
Filter and rank images by text prompts with CLIP models
For data collection, we provide an automated pipeline for obtaining images from publicly available sources using Supervisely Apps like Flickr and Pexels. Smart data querying and filtering can be done with CLIP.
1.1. Automated image collection
Our initial data collection strategy was automated web scraping from Flickr and Pexels. We targeted approximately 2 000 raw textures with keyword searches such as "asphalt", "asphalt texture", "wall texture", "concrete texture", "stone texture", and similar terms.
However, it's noteworthy that automated processes can often fetch a mix of relevant and non-relevant images. In our case, a significant portion of these images didn't align with our requirements:
 Relevant and non-relevant examples
Relevant and non-relevant examples
1.2. Filtering non-relevant images with CLIP
To refine our dataset, we used OpenAI's CLIP model, known for its effectiveness in determining the relevance of an image relative to a given text. After CLIP processing, our pool of images was reduced from 2000 to about 350.
While the CLIP proved to be a great method for removing obviously unrelated images, some ambiguous images still required manual viewing. Learn more about how to use CLIP model in this blog post: How to run OpenAI CLIP with UI for Image Retrieval and Filtering.
1.3. Manual review
Our team manually filtered out the remaining unrelated images and ended up with 226 clear textures :
 Examples of collected textures for synthetic dataset
Examples of collected textures for synthetic dataset
Step 2. Implement procedural crack generation
Cracks, by nature, follow a random and intricate pattern. Reproducing the nuanced randomness and variability seen in real-world cracks is challenging. Of course, simple procedural algorithms produce repetitive or uniform patterns that don't reflect the organic nature of genuine cracks, but they are a good starting point.
We have implemented 3 different types of algorithms for procedural crack generation. Such algorithms simply draw lines in one pixel with controlled input parameters:
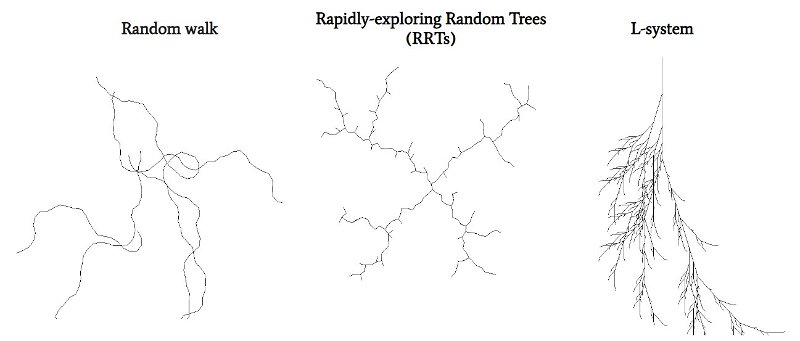 3 types of generative algorithms
3 types of generative algorithms
We tried making our generated cracks by tweaking their thickness and adding some distortion transforms to make the lines more complex. At a glance, placing these cracks on our original textures looked not bad:
 Example of a generated crack placed on top of a texture
Example of a generated crack placed on top of a texture
But the details are very critical to a neural network. We've trained a model on such images, and it immediately overfitted resulting in terrible performance.
Step 3. Composition & Post-processing
This step is about how to overlay generated cracks on textures and how to make the final image as realistic as possible. I think this step is the most challenging and the most crucial at the same time. It requires a bit of ingenuity and insight from the researcher or developer, and it reveals the full potential of training a neural model on synthetic data.
When creating a synthetic dataset, there are several considerations to keep in mind. These considerations influence not only the realism of your dataset but also the subsequent performance of any model trained on it. In short, here are factors affecting model quality when trained on synthetic data:
1. Dissimilarity from real data
If synthetic data fails to capture certain nuances, subtle patterns, or rare cases present in real data, the trained model could suffer when faced with real-world tasks. This dissimilarity might manifest as subtle biases in texture, lighting conditions, or crack patterns. For instance, if cracks in synthetic data tend to follow a certain orientation due to the generation method, the model might struggle with differently oriented cracks in real-world images.
2. Overfitting on synthetic characteristics
Synthetic datasets can sometimes introduce specific characteristics unintentionally. For example, generated lines might be very sharp at the edges. Adding a slight blur or modifying the sharpness of crack edges can make them blend better with the base texture. Otherwise, it leads to overfitting, and the model will segment only those cracks that are sharp at the edges:

3. Lack of Variability
Synthetic datasets might lack the diverse conditions seen in the real world, leading to a model that's not robust to variations. Factors like material composition and lighting conditions can affect how a crack looks. If a synthetic dataset doesn't offer a diverse representation of all potential conditions and factors, the model might not be robust enough.
Step 4. Increase Variability with Style Transfer
It is very difficult to create an algorithm or an environment that will accurately simulate the real world. To overcome this, we improved our algorithm to produce a wider variety of images, some even more challenging than what we see in real life. We incorporated a Style Transfer model, which transforms our generated images, giving them a unique, almost surreal look. This drastically increases the diversity of the data and boosts our model's performance.
![]()
Results
Our final synthetic dataset is sufficient to train a reliable model that achieves a quality comparable to a model trained on real data. In the upcoming posts, we will share the experience gained after training dozens of models on synthetic data, and cover all details of improving compositing and post-processing.
After a large number of experiments on crack generation, we ended up with samples that are looking like this:

Final Dataset Overview
The Cracks Synthetic Dataset is sufficient to train a reliable model that achieves a quality comparable to a model trained on real data. The creation of the dataset involved three primary stages: collecting textures of real materials, procedural crack generation, and post-processing. Post-processing, crucial for achieving realism, focused on integrating cracks naturally into textures. To enhance our dataset's diversity, we incorporated a Style Transfer model.
Dataset contains:
1 558 synthetic images with Ground Truth annotations, 400 of them were post-processed with Style Transfer model. All images have a resolution of 512x512.
Examples
3 different types of crack patterns:

Wide variety of materials:

Used Style Transfer in post-processing. For 400 images we used a Style Transfer model to enrich the diversity of the data:

Differences with real-world data
Our dataset may differ in some characteristics from real data. But despite this, it is sufficient to train a reliable model. Below, we present these characteristics using examples of real data.
Real cracks visually might be more embedded into material:

Real cracks can be found in an enormous variety of patterns and environmental conditions:

Real cracks might occur with other objects:

Conclusion
In this post, we've introduced a Synthetic Crack Dataset for semantic segmentation. We looked at how it was created, what potential problems might be encountered, and what can be done to overcome them and further improve a synthetic dataset.
Soon, we release the next post, which will be dedicated to training a neural network on synthetic data and the experience we have gained in this process.
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



