Human Pose Estimation: all you need to know

Get ready to be impressed by how quickly and accurately Supervisely can estimate human poses using advanced techniques.

Table of Contents
Introduction
This article is part of a series focused on Pose Estimation and aims to provide insights into Human Pose Estimation (HPE). By the end of this post, you will have a clear understanding of what HPE is and how it is applied in practical scenarios.
Additionally, you'll explore various annotation techniques employed in Supervisely to address HPE challenges, including manual labeling and leveraging pretrained models for streamlined annotation.
To learn more about Animal Pose Estimation check out our previous post.
Video tutorial
As usual, we recorded a video tutorial for this post, where we demonstrate how to:
-
Create a keypoints class and set up a framework for defining a pose arrangement.
-
Utilize the ViTPose model either independently or in conjunction with YoloV8 for human pose estimation
What is Human Pose Estimation?
Human pose estimation (HPE) is a computer vision task of detecting and estimating the position of various parts of the human body on images images or videos. This domain focuses on the localization of human body joints, for example, such as elbows and knees, also known as keypoints.
Human pose estimation technology is used in various fields such as:
Human pose estimation enables deep learning models to recognize and analyze human body movements and its interaction with the environment in videos or images for further training. In can be used, inter alia, in
- Healthcare to analyze and then diagnose patient movements during rehabilitation after injury or surgery; for analyzing gait for orthopedic and neurological assessments.
- Fitness and Sports to track and analyze workouts form and technique to prevent injuries; for creating virtual fitness trainers for personalized workouts.
- Entertainment and Gaming to enable gesture-based control in video games and virtual reality (VR) applications.
- Retail and E-commerce to improve virtual try-on experiences for clothing and accessories and enhancing augmented reality (AR) shopping applications.
- Gesture and Communication to create systems that allow users to control technology and devices using gestures and body movements.
- Autonomous Vehicles to improve driver monitoring systems to ensure alertness and safety; for enhancing pedestrian detection and avoidance in self-driving cars, and much more.
 Dancer's pose estimation
Dancer's pose estimation
 HPE in sports
HPE in sports
Types of Human Body Models
The entire human body can be represented by three different types of models:
-
Kinematic Model|Skeleton-based model. This adaptable and user-friendly model depicts an object by defining it as a collection of interconnected keypoints that symbolize bones or joints with meaningful relationships. The skeletal pose estimation model is a widely employed tool for illustrating the interrelations among various body parts, thereby facilitating the emulation of natural motions and postures. Nevertheless, its capacity to convey information concerning an object's texture and shape is restricted. This model is applied for both 2D and 3D pose estimation tasks.
-
Planar Model|Contour-based model serves as a valuable tool for recognizing and analyzing object shapes. In this model, body parts are typically approximated using multiple rectangles that closely mimic the contours of the human body. This approach proves particularly beneficial for tasks involving the segmentation and classification of objects. It is primarily employed for 2D pose estimation.
-
Volumetric model|Volume-based model. This model represents objects as three-dimensional structures that fill space. The depiction of body poses is made to look as real as possible, using shapes like cylinders and cones. It is used for 3D pose estimation.
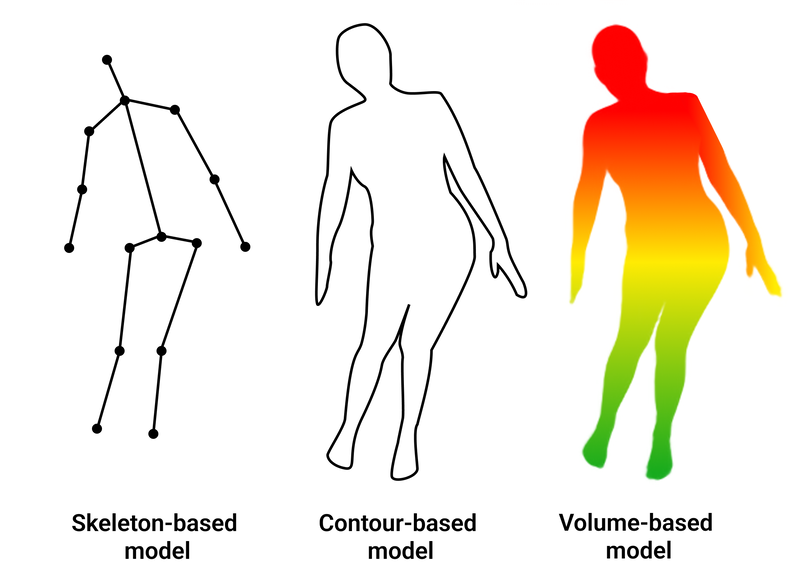 Human body models
Human body models
Moving forward, we will focus on 2D skeleton-based Human Pose Estimation techniques, as 3D typically starts with 2D algorithms before transitioning into the 3D space:

2D detection of keypoint and 3D prediction for HPE task, image credit - MIT License
HPE skeleton-based model: how to label your data
Human pose estimation is a complex task, as it involves handling dynamic changes like clothing variations, obstructions, viewing angles, and environmental factors. Maintaining accuracy in diverse conditions, including varying lighting and weather, poses an additional challenge, particularly when precisely locating small joints like the nose in images.
Examples of human keypoints may include like "right shoulder," "left knee," "right wrist," and others. Various tasks may necessitate distinct sets of keypoints, as demonstrated in the comparison of skeletons utilized in two open-source keypoint datasets below:
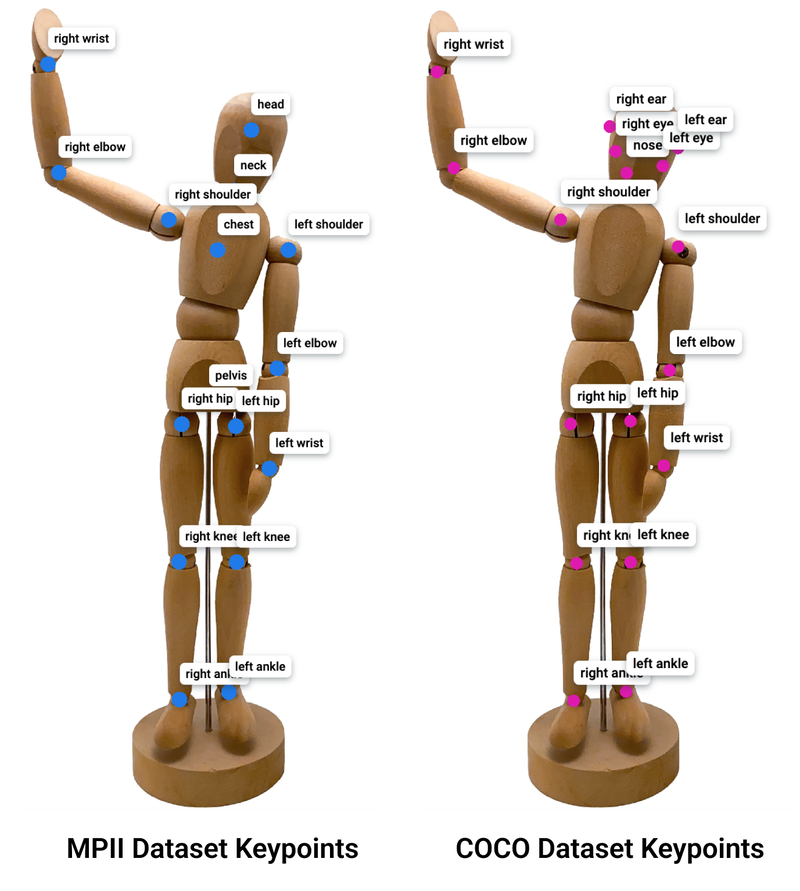 Example of location and names of keypoints
Example of location and names of keypoints
Human pose estimation typically consists of two primary steps: keypoint detection and estimation. Detection identifies the presence of a human in an image, while keypoint estimation involves determining the coordinates of specific body joints. This process is commonly visualized as a "skeleton" connecting these keypoints to represent the human pose.
Below we will present an overview of manual and automated techniques employed in Supervisely for Human Pose Estimation, accompanied by concise descriptions of each approach.
Definition of keypoint skeleton template
The skeleton template with keypoints serves as the basis for the model to understand the human pose and can vary depending on the task. For example, in a gesture recognition task, the focus would be on logically connecting the points of the hand and fingers. In a sports context, the focus shifts to larger joints, such as elbows and knees, which are more important for motion analysis.
To get started, you need to create a keypoint shape class. This class should define the main keypoints that characterize the pose.
Manual annotation tools
Manual annotation tools allow annotators to accurately label these keypoints on images, creating a labeled dataset. Then, this dataset can be used to train the neural network model to predict keypoints on new unlabeled images. In order to label keypoints on images manually, carefully place a predefined skeleton on the object, refining keypoints as needed.
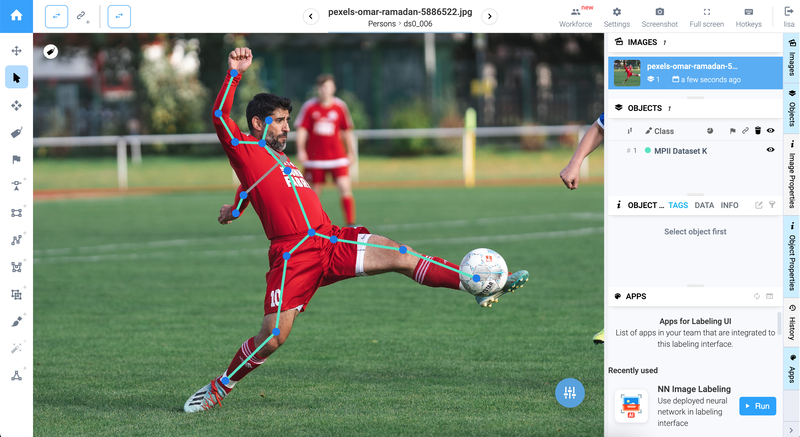 The gray line is connected to the concealed (non-visible) sections of the human
The gray line is connected to the concealed (non-visible) sections of the human
⚠️The manual process requires a great deal of attention to detail to ensure accurate estimation of nuances in human poses.
AI-assisted annotation with VitPose
Modern Human Pose Estimation techniques heavily rely on deep learning, specifically Convolutional Neural Networks (CNNs). These networks are trained on large datasets, learning to detect patterns and relationships within images. Recently, vision transformers have shown great potential in many vision tasks. Inspired by their success, different vision transformer structures have been deployed for pose estimation task.
Explore our blog post ViTPose — How to use the best Pose Estimation Model on Humans & Animals to get in-depth knowledge about this state-of-the-art pose estimation model.


NN Image Labeling
Use deployed neural network in labeling interface
Remember that to run GPU-dependent apps on your machine you need to connect a computer with a GPU to your Supervisely account. You can connect multiple computers for enhanced computational resources. Watch a 1.5-minute how-to video to learn more.
To apply ViTPose model, you need to set up a few parameters, and then you can proceed with automated pose estimation. Beforehand, do not forget to highlight the necessary bodies in the image with bounding boxes. For more details refer to video tutorial attached to this blog post.
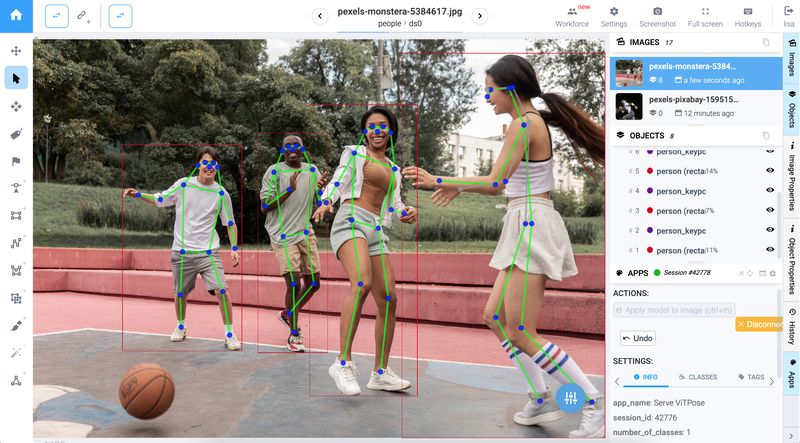 Result of Automatic Pose Estimation using the ViTPose model
Result of Automatic Pose Estimation using the ViTPose model
Autolabeling pipeline: detection using YOLOv8 + pose estimation using ViTPose
An efficient approach to preprocessing large datasets is to combine object detection with pose estimation. YOLOv8, a popular object detection model, can be used to identify people in an image. Subsequently, a pose estimation model such as ViTPose can be used to estimate their poses. This pipeline reduces the need for manual annotation, making the data labeling process more efficient and automated.
Serve YOLOv8 | v9 | v10 | v11
Deploy YOLOv8 | v9 | v10 | v11 as REST API service

Apply Detection and Pose Estimation Models to Images Project
Label project images using detector and pose estimator
By launching the Apply Detection and Pose Estimation Models to Images Project application and adjusting a couple of settings, you can seamlessly merge both tasks without any hassle. The application will take care of everything for you effortlessly. For more details refer to the video tutorial.
Conclusion
Human pose estimation is an advanced technology with great potential for various industries. With the application of advanced computer vision techniques and optimized labeling processes, the development of human pose estimation continues to gain momentum.
By following the guidelines presented in this article, you will be able to achieve optimal human pose estimation results while minimizing time and eliminating the possibility of errors.
Follow us to learn more about pose estimation and other exciting aspects of this topic!
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



