ViTPose — How to use the best Pose Estimation Model on Humans & Animals

The complete guide on automatic body pose estimation of animals and humans on your images in Supervisely.

Table of Contents
Manual skeleton annotation for computer vision tasks of body pose estimation of humans and animals is time-consuming and expensive. In this tutorial you will learn how to use state-of-the-art pose estimation model ViTPose in combination with model-assisted tools in Supervisely to automatically pre-label pose skeletons of animals and humans in the images from your custom dataset.
Video tutorial and step-by-step guide
In this step-by-step video guide, we demonstrate how to:
-
Create a custom keypoint skeleton template
-
Manually annotate body poses on images with the defined skeleton template in Supervisely Labeling Toolbox
-
Run Serve VitPose Supervisely App to deploy pre-trained publicly available ViTPose model in a few clicks. In the demo, we utilized a checkpoint for animal pose detection and estimation, but you have the flexibility to choose any model checkpoint for the human pose estimation task if needed.
-
Get model predictions and perform model-assisted annotation to speed up manual labeling of cow body poses.
-
Use ViTPose in combination with YOLOv8 object detection model to label all images at once in your dataset automatically.
What is Pose Estimation?
Pose estimation is a computer vision task of localizing and classifying anatomical body keypoints (joints) in images or videos.

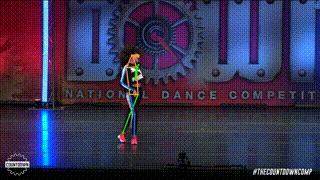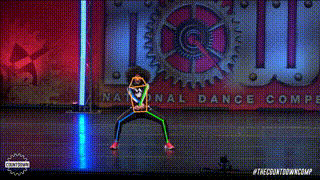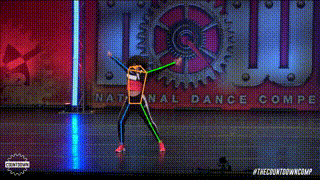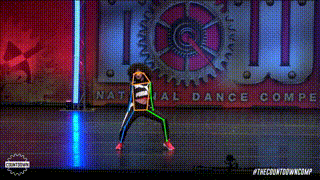

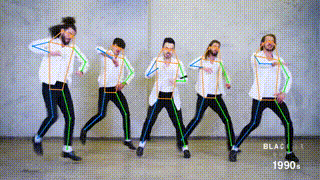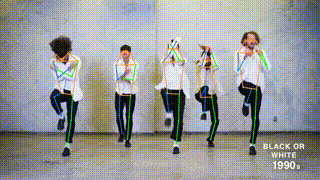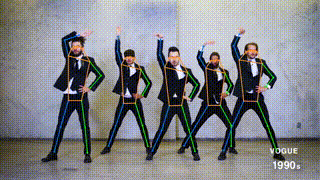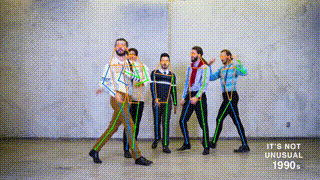
What is ViTPose?
ViTPose is a powerful neural network designed for general body pose estimation in computer vision tasks. To make the most of this model, simply ensure you provide it with the bounding boxes centered around the objects of interest. You can either put the bounding boxes manually or use an object detection model for this purpose. It's worth noting that ViTPose currently ranks as a state-of-the-art performer in various benchmarks, including the COCO test-dev dataset according to paperswithcode (click image to zoom).
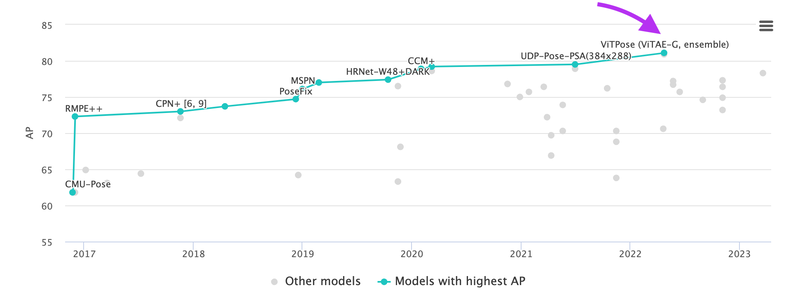 ViTPose model is number one in Pose Estimation Leaderboard on MS COCO Keypoint test-dev and obtains 81.1 AP.
ViTPose model is number one in Pose Estimation Leaderboard on MS COCO Keypoint test-dev and obtains 81.1 AP.
The VitPose architecture builds upon the foundation of plain vision transformers. Its backbone, the encoder, relies on non-hierarchical vision transformers to extract image features. VitPose incorporates a lightweight decoder for pose estimation. This model strikes a favorable balance between inference speed (throughput) and performance (accuracy) by harnessing the scalable model capacity and the high parallelism inherent in transformer-based approaches.
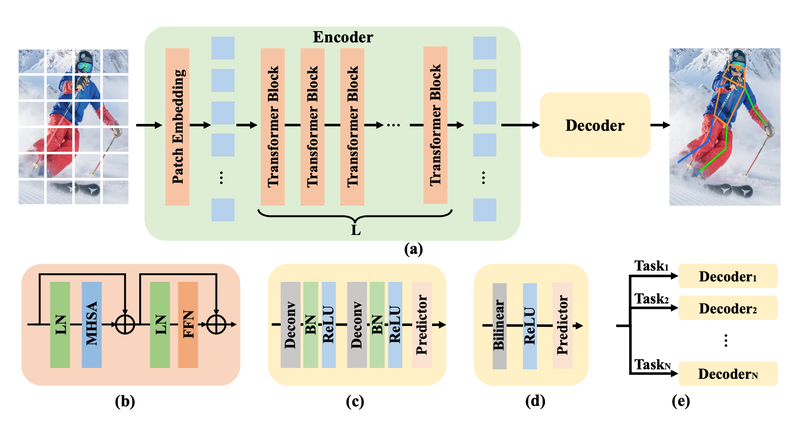 (a) The framework of ViTPose. (b) The transformer block. (c) The classic decoder. (d) The simple decoder. (e) The decoders for multiple datasets.
(a) The framework of ViTPose. (b) The transformer block. (c) The classic decoder. (d) The simple decoder. (e) The decoders for multiple datasets.
Thus, ViTPose authors keep the structure as simple as possible and try to avoid fancy but complex modules, even though they may improve performance. To this end, authors simply append several decoder layers after the transformer backbone to estimate the heatmaps w.r.t. the keypoints, as illustrated in the accompanying figure. For simplicity, they do not adopt skip-connections or cross-attentions in the decoder layers but simple deconvolution layers and a prediction layer.
Specifically, given a person instance image X as input, ViTPose first embeds the images into tokens via a patch embedding layer. Subsequently, the embedded tokens are processed by several transformer layers, each of which is consisted of a multi-head self-attention (MHSA) layer and a feed-forward network (FFN).
The ViTPose model has several notable attributes:
-
Structure simplicity: it maintains a straightforward architecture by leveraging plain vision transformers, avoiding the integration of complex modules.
-
Scalability: ViTPose permits the adjustment of model size by stacking different numbers of transformer layers and manipulating feature dimensions as needed.
-
Flexibility: the model demonstrates adaptability in various aspects, including pre-training data sources, resolution, attention types, and fine-tuning . It can effectively undergo pre-training on datasets lacking pose data and subsequently fine-tune on pose estimation datasets.
-
Transferability: ViTPose uses knowledge distillation to train large models and enhance the performance of smaller ones by transferring knowledge from the larger models.
Step 1. Connect your GPU
In Supervisely it is easy to connect your own GPU to the platform and then use it to run any neural networks on it for free. To connect your computer with GPU, please watch these videos for MacOS, Ubuntu, any Unix OS or Windows.
Step 2. Run app to deploy ViTPose model

Run Serve ViTPose app on your computer, select one of the pre-trained checkpoints and press Deploy button.
The model is integrated into Supervisely with the following 11 pre-trained checkpoints for humans and four-leg animals. Within Supervisely, users have the flexibility to choose and deploy any of these available models as per their specific requirements.
| Model | Size | Pretrained | Resolution | AP | AR |
|---|---|---|---|---|---|
| ViTPose small classic for human pose estimation | 93 MB | COCO | 256x192 | 73.8 | 79.2 |
| ViTPose base classic for human pose estimation | 343 MB | COCO | 256x192 | 75.8 | 81.1 |
| ViTPose large classic for human pose estimation | 1.15 GB | COCO | 256x192 | 78.3 | 83.5 |
| ViTPose huge classic for human pose estimation | 2.37 GB | COCO | 256x192 | 79.1 | 84.1 |
| ViTPose base simple for human pose estimation | 328 MB | COCO | 256x192 | 75.5 | 80.9 |
| ViTPose large simple for human pose estimation | 1.13 GB | COCO | 256x192 | 78.2 | 83.4 |
| ViTPose huge simple for human pose estimation | 2.35 GB | COCO | 256x192 | 78.9 | 84.0 |
| ViTPose+ small for animal pose estimation | 177 MB | AP10K | 256x192 | 71.4 | - |
| ViTPose+ base for animal pose estimation | 559 MB | AP10K | 256x192 | 74.5 | - |
| ViTPose+ large for animal pose estimation | 1.72 GB | AP10K | 256x192 | 80.4 | - |
| ViTPose+ huge for animal pose estimation | 3.47 GB | AP10K | 256x192 | 82.4 | - |
ViTPose model can detect body joints for most of the four-legs animal species including alouatta, antelope, beaver, bison, bear, bobcat, buffalo, cat, cheetah, chimpanzee, cow, deer, dog, elephant, fox, giraffe, gorilla, hamster, hippo, horse, jaguar, leopard, lion, marmot, monkey, moose, mouse, otter,panda, panther, pig, rabbit, raccoon, rat, rhino, sheep, skunk, snow_leopard, squirrel, tiger, uakari, weasel, wolf and zebra.
Step 3. Use ViTPose in labeling toolbox

NN Image Labeling
Use deployed neural network in labeling interface
Run this Inference App directly within the labeling tool and connect to your deployed model from the Step 2 above. Simply put a bounding box around an object or choose an existing one and press Apply model to ROI button. The selected object will be automatically cropped from the image and transmitted to the model, with real-time predictions displayed on the screen for your convenience.
By leveraging the keypoints predicted by the model, you can effectively streamline the manual annotation process, reducing the need for extensive manual labor. Your primary task will involve reviewing and correcting any inaccuracies or errors detected by the model.
Step 4. Inference on all images in your dataset

Apply Detection and Pose Estimation Models to Images Project
Label project images using detector and pose estimator
Serve YOLOv8 | v9 | v10 | v11
Deploy YOLOv8 | v9 | v10 | v11 as REST API service
VitPose model lacks the capacity to simultaneously detect multiple skeletons within a single image out-of-the-box. To address this limitation, it should be used alongside an object detection model. Here's the workflow: firstly, the object detection model identifies and predicts bounding boxes around all objects in the image. Then, the VitPose model is applied to each of these bounding boxes to predict keypoint skeletons. This collaborative approach ensures accurate skeleton detection for multiple objects within a single image.
In addition to the ViTPose model already deployed, you'll need to set up one of the object detection models. You have the option to either use a pre-trained model or a custom checkpoint. In Supervisely, we've integrated the leading object detection toolboxes, including YOLOv5, YOLOv8, MMDetection and Detectron2. You have the freedom to select any model from these toolboxes.
Moreover, you can effortlessly train your own custom object detection models without the need for coding. Explore our tutorial on how to train custom YOLOv8 model on your dataset.
Conclusion
This tutorial offers a smart way to avoid the time-consuming and expensive process of manually labeling body poses in computer vision tasks for both humans and animals. It shows how to use the advanced ViTPose model along with Supervisely to quickly pre-label pose skeletons in your custom image datasets. From creating templates and manual labeling to deploying ViTPose and integrating object detection, this tutorial simplifies the process. ViTPose's user-friendly features make it an excellent choice for speeding up annotation tasks of pose estimation of humans and animals on images. Sign up and try to reproduce this tutorial in our free Community Edition.
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
CTO and Founder at Supervisely, PhD in Computer Vision
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



