How to Train a Model with Only 62 Labeled Images using Semi-Supervised Learning

This experiment reveals the potential of semi-supervised learning, proving the opportunity to train a model using only a small fraction of labeled data.

Table of Contents
Introduction
In the recent blog post - Unleash The Power of Domain Adaptation with HRDA, we've delved into training the HRDA model using synthetic data and Domain Adaptation for the crack segmentation task, and broke down all the ingenious techniques that HRDA uses. In today's post, we're going to expand our horizons by exploring the power and potential of Semi-supervised Learning with the HRDA model.
The primary aim of this post is to illustrate how you can train a robust model while significantly minimizing the manual effort and cost of data labeling. Imagine having to label only a small fraction of your dataset and still achieving comparable results to a model trained on the entire dataset!
What is Semi-supervised Learning?
In the realm of Machine Learning, we typically deal with two primary types of learning: supervised (where we use labeled data) and unsupervised (where we deal with raw, unlabeled data). Semi-supervised learning strikes a harmonious balance between these two, utilizing both labeled and unlabeled data for training. This methodology is particularly beneficial when labeling data is resource-intensive or costly.
An Overview of Sugar Beet 2016 Dataset
For this experiment we utilized a part of Sugar Beet 2016 Dataset. This dataset is designed for segmenting beets and weeds from top-view soil snapshots. In total, it contains ~11,000 RGB images with two object classes: sugar beet and weed.
The dataset is quite challenging. If you inspect the images, you'll find that they aren't high-resolution, coupled with dim lighting conditions. Moreover, the tiny weeds often blend seamlessly with the soil, making them barely discernible to the naked eye.




Experiment Setup
Here are the list of steps to reproduce the experiments
1. Sample Representative Subset
Our first goal was to see if we can take just a handful of images to train a robust model. We could sample these images randomly, but we won't leave this important task to a random generator. Here is the trick: we're going to choose images as diverse as possible.
To achieve this diversity, we utilized the embeddings from a pre-trained model. In Supervisely we have Explore Data with Embeddings app for that.
What are these embeddings? In a nutshell, after running an image through a network, we can extract the embeddings. It's just a vector of numbers. Imagine these embeddings as a higher-dimensional representation of images, capturing intricate patterns and features. By projecting these embeddings onto a 2D plane (a technique often used in dimensionality reduction), we can visualize the diversity in our dataset. Images that are further apart on this plane are distinct from each other.
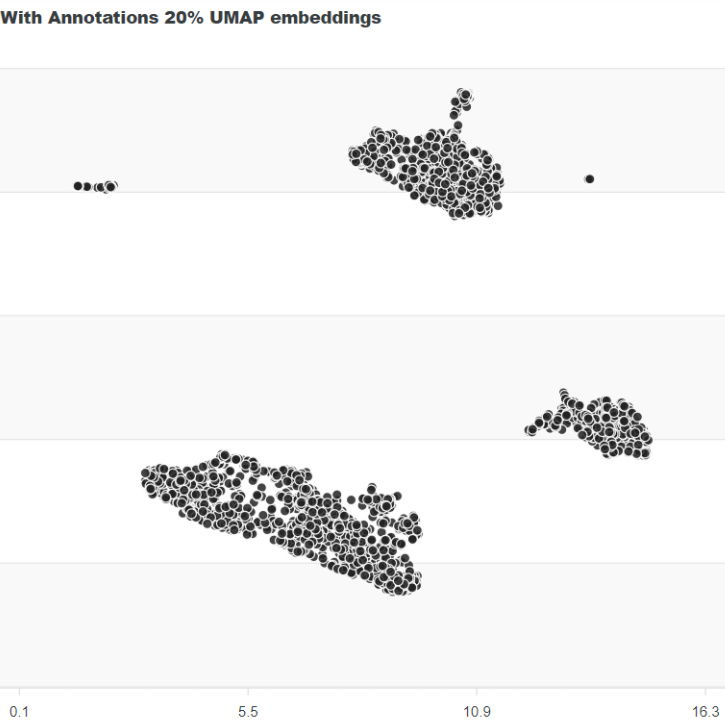 The Diversity of the Dataset
The Diversity of the Dataset
We've projected the embeddings with UMAP and then cherry-picked some diverse images, ending up with only 62 samples. The resulting dataset has been uploaded to Dataset Ninja for this tutorial:










Supervisely HRDA Plants Demo
The Supervisely HRDA Plants Demo dataset is a part of Sugar Beets 2016 dataset, which is used in the experiment "How to Train a Model with Only 62 Labeled Images using Semi-supervised Learning" conducted by Supervisely Team. The experiment reveals the potential of semi-supervised learning and proves the opportunity to train a good model using only a small fraction of labeled data, thereby significantly minimizing manual effort and the cost of data labeling..
Get in Dataset Ninja
2. Ensuring Quality Annotations
Rather than blindly trusting external annotators, we examined the quality of annotations for our chosen 62 images. Our suspicions were confirmed as we found inconsistencies: mixed-up classes, missing annotations for entire objects, and sometimes, unlabeled parts. We fixed these annotations manually to ensure utmost precision. By the way, we took advantage of RITM Interactive Segmentation (or Smart Tool) which speeds up manual labeling dozens of times. RITM is available in our Supervisely Platform.

RITM interactive segmentation SmartTool
State-of-the art object segmentation model in Labeling Interface
3. Adding Unlabeled Data
In the manner of semi-supervised learning, we supplemented our dataset by unlabeled images. We randomly sampled another 20% (2000 images) and removed their labels. This was done to challenge and assess the HRDA's potential in a semi-supervised setting.
4. Training the Models
With our data ready, we embarked on the training journey. We trained HRDA in a semi-supervised mode using our curated dataset. For benchmarking purposes, we also trained a segmentation model, Segformer, on the entire dataset (all 11,000 images). This model served as our reference.
Train HRDA
Train HRDA model for segmentation in semi-supervised mode
In training dashboard correctly select the datasets with annotated images, unlabeled data and validation.
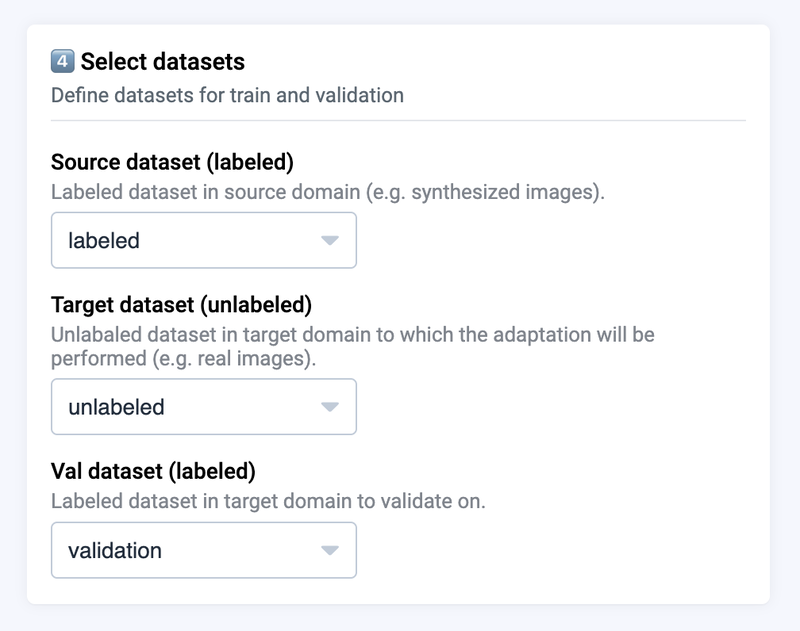 Define training splits for your data
Define training splits for your data
Results on Validation
The HRDA model, trained on merely 62 labeled images and 20% unlabeled, yielded a performance almost as good as the Segformer model trained on the full dataset.
Here is a quantitative comparison of the mIoU metrics:
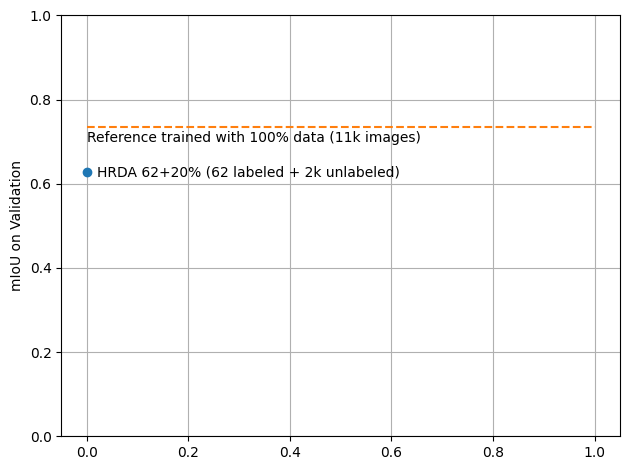 mIoU on Validation
mIoU on Validation
| Model | Training Data | mIoU |
|---|---|---|
| HRDA | 62 labeled + 2,222 unlabeled (20%) | 0.6271 |
| Segformer (Reference) | 11,110 labeled | 0.7354 |
While the numbers speak volumes, visual comparisons of the predictions confirms good HRDA performance. Given the visual complexity of the dataset, both models had their own good moments and mistakes. Intriguingly, the reference model's predictions weren't consistently superior to the HRDA's, despite its advantage in training data.

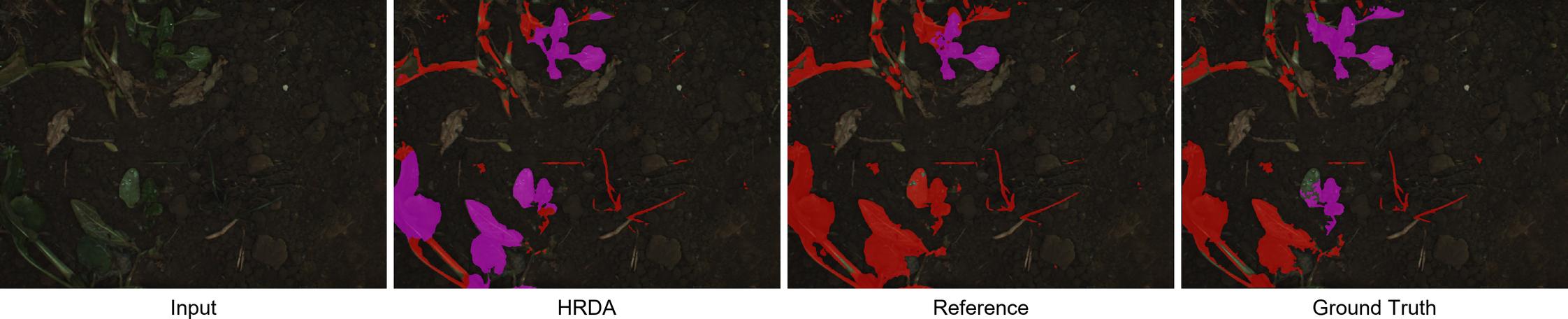
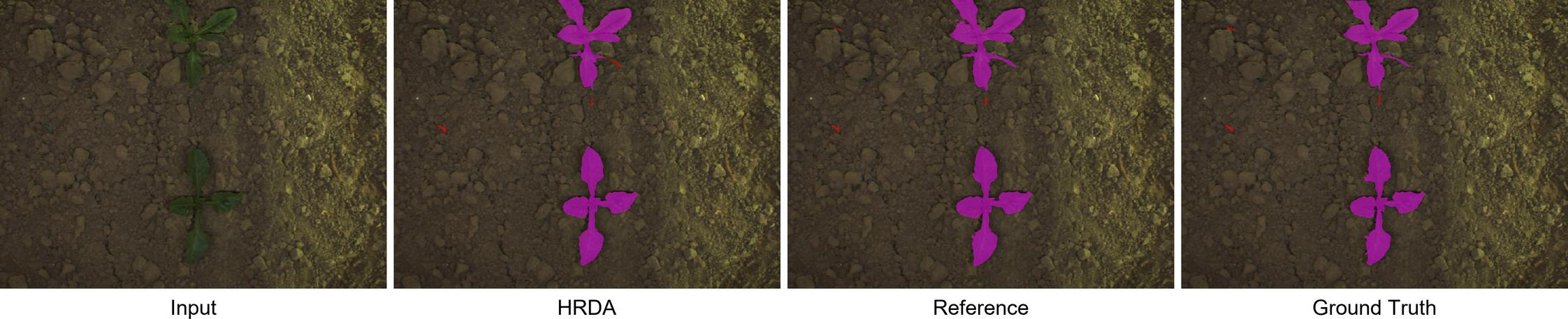
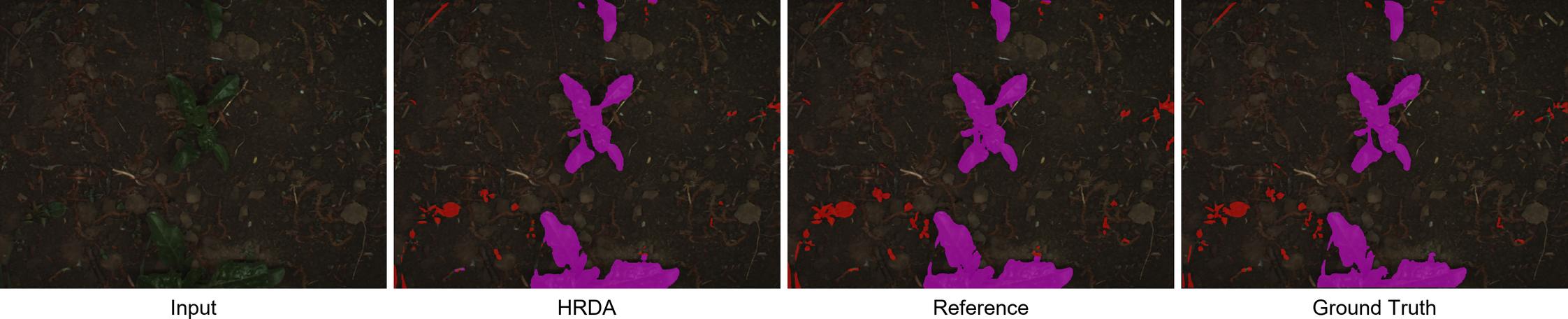
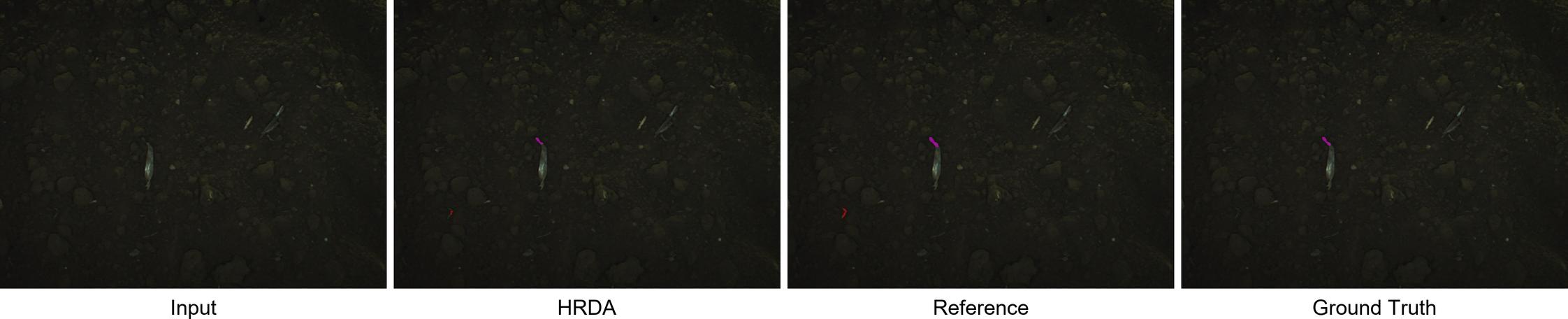

Conclusion
The landscape of semi-supervised learning is vast, promising, and undoubtedly, the future for many applications where data labeling is resource-intensive. Our experiment with HRDA highlights its effectiveness and potential in this area. The key takeaway is the huge potential of leveraging both labeled and unlabeled data, combined with powerful models like HRDA, to achieve remarkable results even when manual resources are limited.
In upcoming posts, we'll continue our journey into advanced methodologies in data science. Stay tuned, and happy learning!
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



