Mastering Labeling Jobs: Your Ultimate Guide

Discover the power of collaborative annotation through labeling jobs. Learn how to harness teamwork for efficient and accurate data annotation.

Table of Contents
Optimizing Data Annotation Challenges with Labeling Jobs
When performing data annotation for big datasets, excellent team coordination is crucial. With the сareful labeling, efficient collaboration within the team and strict quality control of the input annotation, we get high-quality data for further model training. However, there are several complexities and challenges in the data annotation process:
-
Subjectivity: Annotators' subjective judgment often occurs in data labeling. Diverse annotators may interpret the data differently, leading to disagreements in the labeling.
-
Misunderstanding of the task: Annotators may not fully understand the purpose and requirements of the task, especially if they are inexperienced. This can lead to errors in data annotation.
-
Iterations: During the performing of a task, new data annotation requirements may arise, or data may need to be re-labeled due to changes in the job.
-
Tasks Distribution: Assigning tasks to annotators and ensuring a balanced workload can be challenging.
-
Review and statistics: Monitoring and analyzing annotation statistics is essential. It can be complex to interpret these statistics and make informed decisions based on them.
To ensure that all team members understand and communicate effectively and minimize these complexities, Supervisely suggests using an effective tool known as Labeling Jobs. This tool helps to make the labeling process more structured and harmonized, improving the quality and efficiency of the team's work.
What are the Labeling Jobs?
Labeling jobs is a powerful tool for efficiently organizing and distributing data annotation tasks within a team. It is designed to ensure that annotators work on well-defined and manageable portions of the dataset, follow consistent guidelines, and contribute to the overall success of the annotation project while maintaining data quality and accuracy. It is a critical component of effective team coordination in data annotation efforts.
Benefits of the Labeling Jobs functionality include:
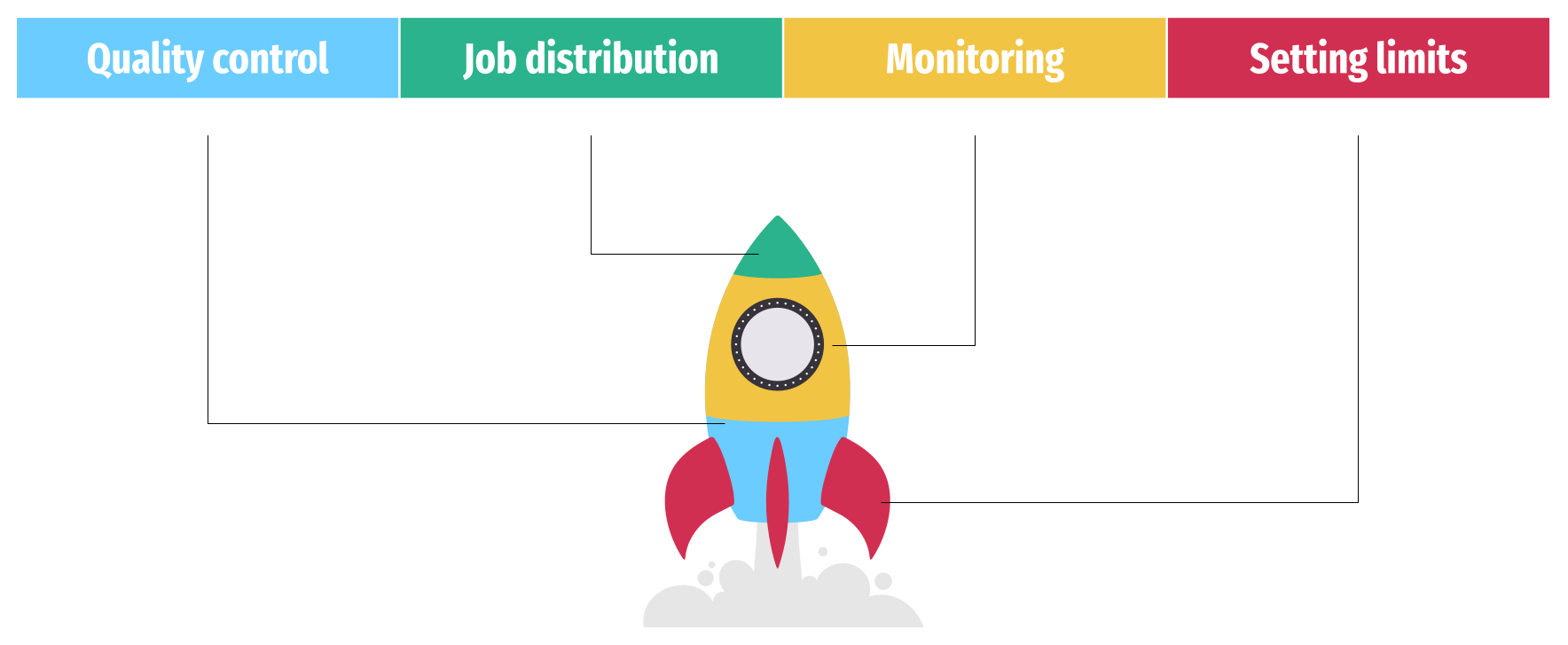
-
Annotation quality control system, including inspections and the ability to send materials for re-labeling if necessary.
-
Distribution of annotation tasks among team members. Dividing the work process into individual jobs assigned to specific team members helps avoiding mutual overlap when working on the same job simultaneously.
-
Formulating technical requirements and establishing restrictions on using classes to eliminate subjective errors.
-
Monitoring the status of the annotation process in real-time with the ability to iterate to improve results.
-
Establishing limited access to specific data sets within the assignment to ensure information confidentiality.
Distribution of roles within the Labeling Jobs
Roles define what activities members can perform within a team. To organize teamwork efficiently, each member is assigned with a different role in the Members page. Depending on their specific requirements, a single user can assume various roles within different teams. For example, a team Manager can invite new members, while a Reviewer does not have this ability.
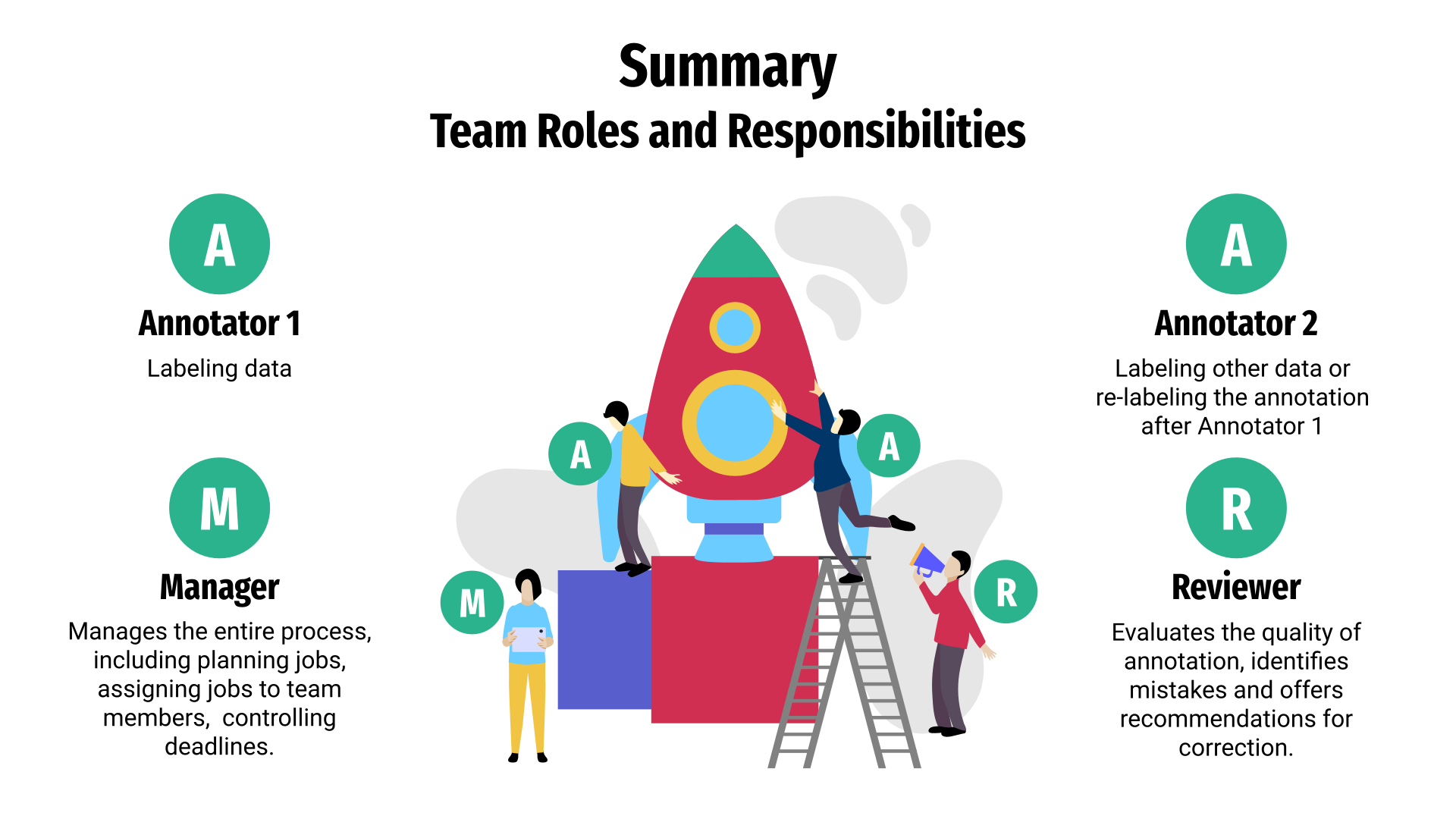
Labeling Jobs involve the following roles:
📋 Manager creates a Labeling Job and controls the entire process of the team’s work.
The Manager initiates Labeling Jobs, ensuring that Annotators receive explicit instructions for data annotation. These labeling descriptions serve to clarify the criteria and prerequisites for accurately annotating data. All descriptions will be in the Info section.
The Manager can also efficiently manage the annotation process and monitor its progress.
When the Labeling Job is completed, the Manager has the ability to view the statistics for analysis of the team's performance. The statistic is available for each task or individual for each Labeler.
 Manager's responsibilities and permissions
Manager's responsibilities and permissions
🛠️Annotator, also called Labeler, whose main task is to label strictly defined data.
The Labeler role restricts the user's access solely to the Labeling Jobs page, with no permissions to view other pages. This role is typically assigned to individuals who are responsible for performing annotation tasks and data labeling without the need for broader system privileges. They can view the specific Labeling Jobs they are assigned to, acomplish them, and submit for review. Annotators cannot create new classes or use other applications or Neural Networks.
 Annotator's responsibilities and permissions
Annotator's responsibilities and permissions
🔍 Reviewer is responsible for checking annotations and, if necessary, sending jobs for re-annotation. Similar to the Manager role, the Reviewer has the ability to create the Labeling Job and view its statistics, but the primary task of the Reviewer is to check the labeled data.
 Reviewer's responsibilities and permissions
Reviewer's responsibilities and permissions
How to use Labeling Jobs in Supervisely: Step-By-Step Guide
Watch our concise video tutorial on using Labeling Jobs in the Supervisely platform to unlock the full potential of collaboration at scale.
Before you start
Make sure that you have:
- dedicated Team assigned with proper roles
- necessary projects for annotation with relevant properties (clasess/figures/tags) defined
Step 1. Create Labeling Job
To create the Labeling Job either Manager or Reviewer shall:
-
Create and assign a Title in the
Labeling Jobstab. -
Provide a description for Annotators.
Markdown or Labeling Guides may be used to provide a detailed task description with photos, videos, and examples of annotations or correct/incorrect labeling.
-
Assign Reviewer and Labelers to complete the Labeling Job.
-
Select the data to annotate.
-
Provide the Annotator with a list of available classes and tags, along with the maximum number of figures and tags per item.
-
Filter data for labeling by various criteria, including tags or by limiting the number of items to be annotated. By default, the entire dataset will undergo the annotation process.
Once the process of setting up the Labeling Job is completed, the Manager or Reviewer will be redirected to the Labelling Jobs page displaying a separate task for each Labeler.
Step 2. Complete the Job
The Labeler performs the assigned task in Labeling Job as follows:
-
Reads the technical specifications and goes to the specified annotation toolbox.
-
Labels the data with pre-defined classes.
-
Clicks the
Confirmbutton whan the annotation is done.After annotating the entire dataset, the Labeler pushes
Submitto send the annotation for the review. After that, the Labeling Job will be marked as completed and will be removed from the list of Labeling Jobs assigned to this Annotator.
Step 3. Review and Quality Control
The Reviewer usually follows these guidelines:
-
Reads the technical specifications and goes to the annotation toolbox.
-
Accepts 👍 or Rejects 👎 the annotations made by the Labeler.
-
Once the reviewing process is finished for all data in the dataset, the Labeling Job may be finalyzed.
If any annotations were rejected, the annotation process is restarted. Data will be sent for re-annotation in a new Labeling Job.
Labeling Job Statistics
📊Manager and Reviewer can view statistics for each labeling job by clicking Stats button.
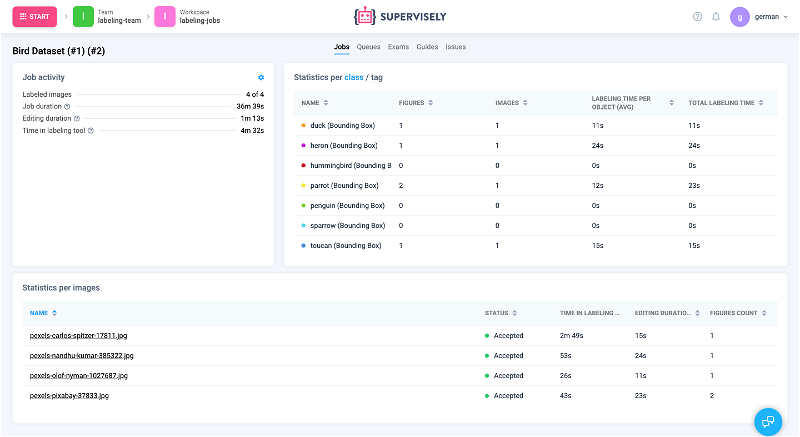 Labeling job statistics
Labeling job statistics
Export
You have the option to retrieve activity data from either a labeling job or a team member in the form of a .csv file. Moreover, you can effortlessly export accepted items such as images, videos, point clouds, and DICOMs from the dataset in Supervisely format following the labeling job review.
Export Items After Review
Export items after the passing labeling job review

You can find and apply more supplementary applications on the Collaboration at scale topic in the Collaboration section of Supervisely Ecosystem.
 Additional Applications
Additional Applications
Conclusion
Labeling Jobs is an effective way to optimize your data training process with coordinated teamwork. It ensures that your data is accurately labeled and organized, which in turn streamlines the training process and improves your models' accuracy. By utilizing the right tools and resources, you can make the most of your training data and achieve better results in less time.
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



